쥬피터 노트북 Files에 data 폴더를 만들고 그 안에
아래 csv 파일을 넣고 코드 따라해보세요 :)
[ 예시 1 ]
%matplotlib 은 Rich Outputs 출력 옵션. (Rich Outputs : 도표, 그림, 소리, 애니메이션 등의 outputs )
파이썬에서 데이터를 차트나 플롯(Plot)으로 그려주는 라이브러리 패키지로서 가장 많이 사용되는 패키지.
브라우저에서 바로 그림을 볼 수 있게 해주는 데이터 시각화(Data Visualization) 패키지.
%matplotlib inline
이 명령어를 사용하면 플로팅 명령의 출력이 Jupyter Notebook과 같은 프론트에서 실행하면 결과를 셀 아래 inline으로 표시
import pandas as pd
pandas 라이브러리를 import 한다.
이름은 pd 로 명명한다.
import seaborn as sns
seaborn 라이브러리를 import 한다. (seaborn은 시각화 테마들 사용하겠다고 불러오는 것)
이름은 sns 로 명명한다.
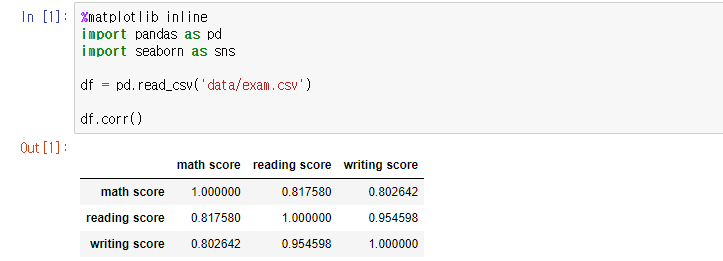
pd.read_csv('파일경로')
read_csv 명령어로 파일을 가져올 수 있다.
엑셀을 가져올땐 read_excel 명령어로 가져오기.
엑셀에서 특정시트를 열고 싶다면 read_excel ( 파일명, sheet_name = '시트명')
df. corr()
데이터프레임 df의 상관계수를 계산
corr() 함수로 간단하게 상관계수 구할 수 있다.
df. head()
데이터프레임 df 의 0~4행 까지 보여달라는 의미
참고로 df. info() 명령어로 데이터 타입 살펴볼 수 있다

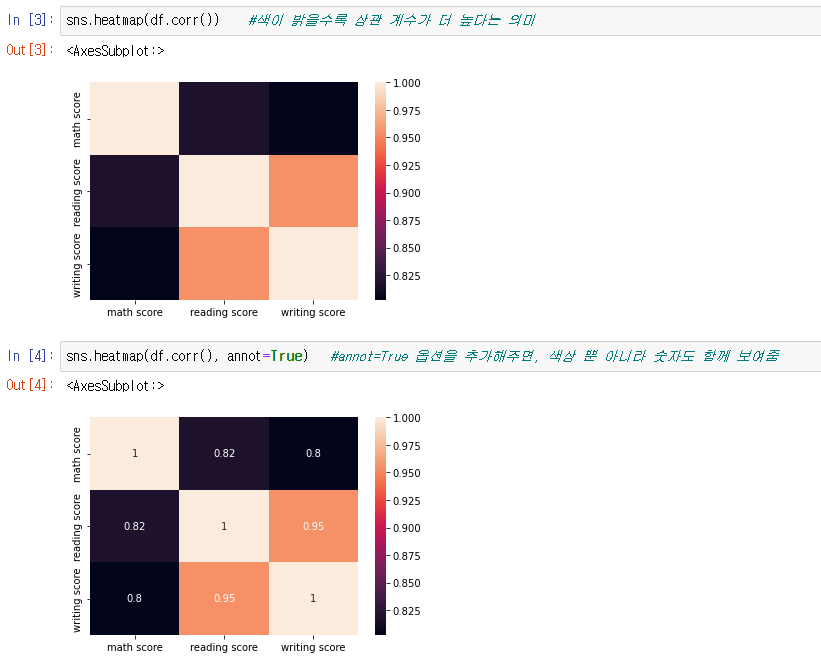
sns.heatmap(시각화할 데이터)
seaborn 라이브러리의 히트맵을 이용해서 시각화 할것이다.
[ 예시 2 ]
쥬피터 노트북에 아래와 같이 코드를 작성한다.
%matplotlib inline
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [8, 5] # [width, height] (inches) 밑에나올 그래프 크기지정
df = pd.read_csv('data/young_survey.csv') # csv 읽어들임
df.corr() # 데이터프레임 df 상관관계 구하기
실행화면>

코드작성
music = df.iloc[:, :19] #로우는 전부 선택, 칼럼은 0부터 19까지만 선택해서 music 에다가 넣음
music.head() # 상위 5 row 보여줘
실행화면 >

코드작성
sns.heatmap(music.corr()) # music 데이터 상관관계를 구하고 그걸 히트맵으로 표현
# x축 45도 각도로 기울이고 싶으면 plt.xticks(rotation=45)
실행화면 >

코드작성
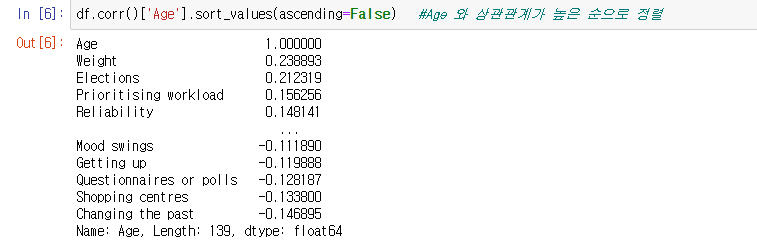
df.corr()['Age'].sort_values(ascending=False) #Age 와 상관관계가 높은 순으로 정렬
실행화면 >
코드작성
interests = df.loc[:, 'History':'Pets'] # df 에서 row는 전부 선택하고 column은 History 부터 Pets 까지 선택해서 interests 에 넣음
interests.head()
실행화면 >

코드작성
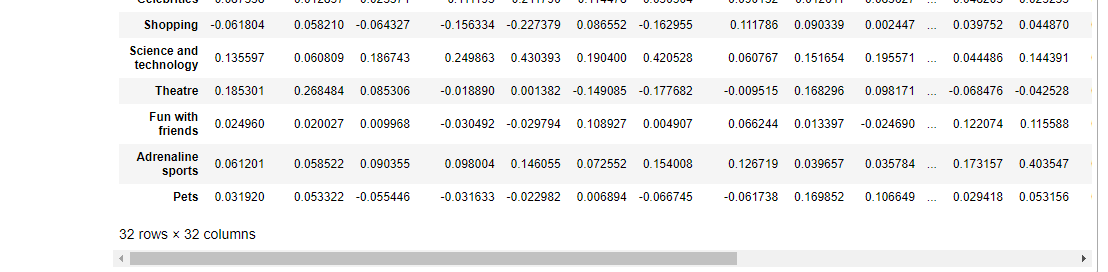
corr = interests.corr()
corr
실행화면 >

.
.
.
코드작성
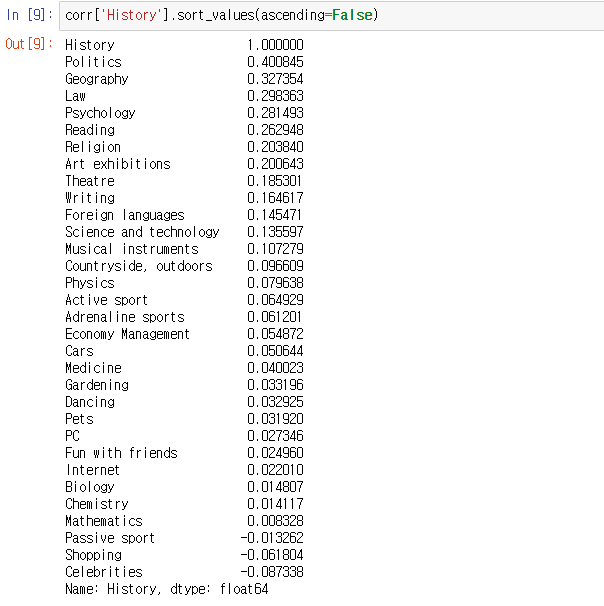
corr['History'].sort_values(ascending=False)
실행화면 >
코드작성
sns.clustermap(corr) # 클러스터는 서로 유사한 것 끼리 묶어줌
실행화면 >

'IT > Python' 카테고리의 다른 글
| 구글 코랩 한글 폰트 설치 코드 (1) | 2025.07.04 |
|---|---|
| 회귀분석 예시 - 광고 지출이 오가닉 유입에 영향을 미칠까? (코드와 해석 포함) (0) | 2024.03.21 |
| [알고리즘] 선형탐색 , 이진탐색 (feat. 파이썬, 시간복잡도) (0) | 2022.02.18 |
| [Python] 팰린드롬 palindrome 거꾸로 해도 같은 단어인지인지 확인하기 (0) | 2022.01.21 |
| [Python] 데이터 시각화 Seaborn 라이브러리 (Jupyter Notebook) (0) | 2022.01.20 |




댓글